One of my goals is a maintenance-free spoken dialogue system that acquires necessary knowledge during human interaction in the open REAL world.
My research interests are auditory scene analysis, knowledge acquisition during dialogue and a new application of audio processing techniques.
Research Area
Microphone Array Signal Processing
Sound Source Localization, Sound Source Separation, Echo Cancellation, DereverberationLanguage Processing
Language Modeling, Word SegmentationAutomatic Speech Recognition
Acoustic Modeling, Robust ASR, Online AdaptationSpoken Dialogue
Dialogue Management, Lexical Aquisition, Development of Real-time SystemApplications
Animal Speech Analysis (Frog, Insect)Main Works
Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno :"Efficient Blind Dereverberation and Echo Cancellation based on Independent Component Analysis for Actual Acoustic Signals," Neural Computation, Vol.24, Issue 1, pp.234-272, 2012.
Ryu Takeda and Kazunori Komatani: "Sound Source Localization based on Deep Neural Networks with Directional Activate Function Exploiting Phase Information," Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP),
pp.405-409, 2016.
Ryu Takeda and Kazunori Komatani: "Frame-wise Online Unsupervised Adaptation of DNN-HMM Acoustic Model from Perspective of Robust Adaptive Filtering," Proceedings of Interspeech, pp.1291-1295, 2020.
Ryu Takeda, Kazunori Komatani and Alexandar I. Rudnicky:
"Word Segmentation from Phoneme Sequences based on Pitman-Yor Semi-Markov Model Exploiting Subword Information,"
Proceedings of IEEE Workshop on Spoken Language Technology (SLT), pp.763-770, Dec. 20, 2018.
Kohei Ono, Ryu Takeda, Eric Nichols, Mikio Nakano and Kazunori Komatani: "Lexical Acquisition through Implicit Confirmations over Multiple Dialogues," Proceedings of Annual SIGdial Meeting on Discourse and Dialogue (SIGDIAL), pp.50-59, 2017.
Ikkyu Aihara, Ryu Takeda, Takeshi Mizumoto, Takuma Otsuka, Toru Takahashi, Hiroshi G. Okuno, Kazuyuki Aihara:"Complex and transitive synchronization in a frustrated system of calling frogs," Physical Review E, Vol.83, Issue 3.031913, 2011.
© 2016 Ryu Takeda
Ryu TAKEDA (Ph.D)
Affiliation
Department of Knowledge Science
SANKEN
The University of Osaka
SANKEN
The University of Osaka
Address
Mihogaoka 8-1, Ibaraki, Osaka 567-0047, Japan
Contact
rtakeda [at] sanken.osaka-u.
Links
Education
March 2006
Bachelor (Eng.), Faculty of Engineering, Undergraduate School of Informatics and Mathematical Science, Kyoto University, Japan
March 2008
Master (Informatics), Department of Intelligence Science and Technology, Graduate School of Informatics, Kyoto University, Japan
March 2011
Ph.D. (Informatics), Department of Intelligence Science and Technology, Graduate School of Informatics, Kyoto University, Japan
Professional Experience
April 2009 - March 2011
Research Fellow of the Japan Society for the Promotion of Science (DC2), Japan
April 2011 - September 2014
Researcher, Cental Research Laboratory, Hitachi, Ltd., Japan
October 2014 - December 2019
Research Associate, The Institute of Scientific and Industrial Research, Osaka University
September 2017 - August 2018
Visiting Researcher, Language Technologies Institute, Carnegie Mellon University
October 2018 - March 2022
JST Presto Researcher
December 2019 - Present
Associate Professor, SANKEN, The University of Osaka
Committee Services etc...
Memberships
The Institute of Electrical and Electronics Engineers (IEEE)
- Treasure, SPS (Signal Processing Society), IEEE Kansai Chapter, JAPAN (January 2017 - December 2018)
The Acoustical Society of Japan (ASJ)
- Councilor, Kansai Chapter of ASJ (June 2025 - Present)
The Information Processing Society of Japan (IPSJ)
- Member of Editorial Committee of IPSJ Journal (July 2021 - May 2025)
Reviews
IEEE Transactions on Audio, Speech and Language Processing
Computer Speech & Language
Speech Communication
Signal Processing (elsevier)
Advanced Robotics
IEICE Transactions on Information and Systems
IPSJ Journal
Journal of Robotics and Mechatronics
International Conference on Acoustics, Speech and Signal Processing (ICASSP 2009, 2018, 2019, 2020, 2021, 2022, 2023, 2024, 2025)
International Conference on Intelligent Robots and Systems (IROS 2011, 2015, 2018, 2019)
International Conference on Robotics and Automation (ICRA 2018)
Annual Conference of the IEEE Industrial Electronics Society (IECON 2015)
Honors and Awards
12th International Joint Conference on Knowledge Graphs Best Research Paper, 9 Dec. 2023.
"Link Prediction Based on Large Language Model and Knowledge Graph Retrieval under Open-World and Resource-Restricted Environment"
Ryu Takeda, Hokuto Munakata, and Kazunori Komatani
"Link Prediction Based on Large Language Model and Knowledge Graph Retrieval under Open-World and Resource-Restricted Environment"
Ryu Takeda, Hokuto Munakata, and Kazunori Komatani
IPSJ Yamashita SIG Research Award, 13 Mar. 2018.
"方向依存活性化関数を用いた Deep Neural Network に基づく識別的音源定位"
武田 龍, 駒谷 和範
"方向依存活性化関数を用いた Deep Neural Network に基づく識別的音源定位"
武田 龍, 駒谷 和範
電気通信普及財団賞 第29回 テレコムシステム技術賞, 2014年3月17日
"Optimized Speech Dereverberation from Probabilistic Perspective for Time Varying Acoustic Transfer Function" (IEEE Transactions on Audio, Speech, and Language Processing, Vol.21, No.7, 2013)
Masahito Togami, Yohei Kawaguchi, Ryu Takeda, Yasunari Obuchi, and Nobuo Nukaga
"Optimized Speech Dereverberation from Probabilistic Perspective for Time Varying Acoustic Transfer Function" (IEEE Transactions on Audio, Speech, and Language Processing, Vol.21, No.7, 2013)
Masahito Togami, Yohei Kawaguchi, Ryu Takeda, Yasunari Obuchi, and Nobuo Nukaga
人工知能学会 2010年度研究会優秀賞, 2011年6月2日
"発語行為レベルの情報を用いた音声対話システムの構築とデータ分析" (SIG-SLUD-B003-02, 2011)
松山 匡子, 駒谷 和範, 武田 龍, 尾形 哲也, 奥乃 博
"発語行為レベルの情報を用いた音声対話システムの構築とデータ分析" (SIG-SLUD-B003-02, 2011)
松山 匡子, 駒谷 和範, 武田 龍, 尾形 哲也, 奥乃 博
人工知能学会 2008年度研究会優秀賞, 2009年6月18日
"ビートトラッキングロボットの構築と評価" (SIG-Challenge-A802-3, 2008)
村田 和真, 中臺 一博, 武田 龍, 奥乃 博, 長谷川 雄二, 辻野 広司
"ビートトラッキングロボットの構築と評価" (SIG-Challenge-A802-3, 2008)
村田 和真, 中臺 一博, 武田 龍, 奥乃 博, 長谷川 雄二, 辻野 広司
Award for Entertainment Robots and Systems (NTF Award) Nomination Finalist (4/649), 22 Sep. 2008.
"A Robot Listens to Music and Counts Its Beats Aloud by Separating Music from Counting Voice", (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2008)
Takeshi Mizumoto, Ryu Takeda, Kazuyoshi Yoshii, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno
"A Robot Listens to Music and Counts Its Beats Aloud by Separating Music from Counting Voice", (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2008)
Takeshi Mizumoto, Ryu Takeda, Kazuyoshi Yoshii, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno
Award for Entertainment Robots and Systems (NTF Award) Nomination Finalist (4/649), 22 Sep. 2008.
"A Robot Uses Its Own Microphone to Synchronize Its Steps to Musical Beats While Scatting and Singing" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2008)
Kazumasa Murata, Kazuhiro Nakadai, Kazuyoshi Yoshii, Ryu Takeda, Toyotaka Torii, Hiroshi G. Okuno, Yuji Hasegawa, Hiroshi Tsujino
"A Robot Uses Its Own Microphone to Synchronize Its Steps to Musical Beats While Scatting and Singing" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2008)
Kazumasa Murata, Kazuhiro Nakadai, Kazuyoshi Yoshii, Ryu Takeda, Toyotaka Torii, Hiroshi G. Okuno, Yuji Hasegawa, Hiroshi Tsujino
RSJ/SICE AWARD for IROS2006 Best Paper Nomination Finalist, 2007/10/31.
"Missing-Feature based Speech Recognition for Two Simultaneous Speech Signals Separated by ICA with a pair of Humanoid Ears" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2006)
"Missing-Feature based Speech Recognition for Two Simultaneous Speech Signals Separated by ICA with a pair of Humanoid Ears" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2006)
IEEE Robotics and Automation Society Japan Chapter Young Award, 2006/10/11.
"Missing-Feature based Speech Recognition for Two Simultaneous Speech Signals Separated by ICA with a pair of Humanoid Ears" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2006)
"Missing-Feature based Speech Recognition for Two Simultaneous Speech Signals Separated by ICA with a pair of Humanoid Ears" (Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2006)
Research Grants
Grant-in-Aid for Scientific Research (B) (Principal investigator), Apr. 2023 - Present
Grant-in-Aid for Scientific Research (A) (Co-investigator), Apr. 2022 - Present
Grant-in-Aid for Scientific Research (B) (Co-investigator), Apr. 2020 - Mar. 2022
JST Presto, Oct. 2018 - Mar. 2022
Grant-in-Aid for Scientific Research (B) (Co-investigator), Apr. 2016 - Mar. 2019
Grant-in-Aid for Young Scientists (B) (Principal investigator), Apr. 2014 - Mar. 2016
Grant-in-Aid for JSPS Fellows (DC2), Apr.2009 - Mar. 2011
Skills
Programming: C/C++, octave (matlab), python
Audio Signal Processing
Interests/Hobbies
Others
- half marathon: 1:39:29 (2010)
- marathon: 3:56:26 (2010)
- Turing as a runner: 2:46:03
© 2016 Ryu Takeda
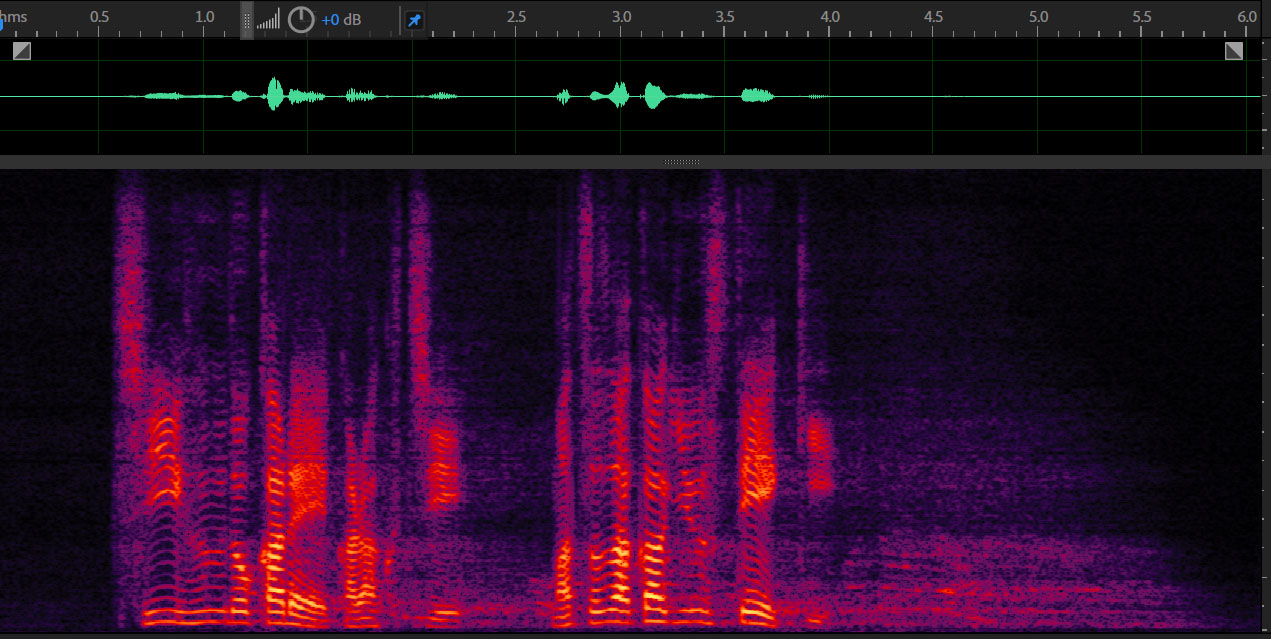
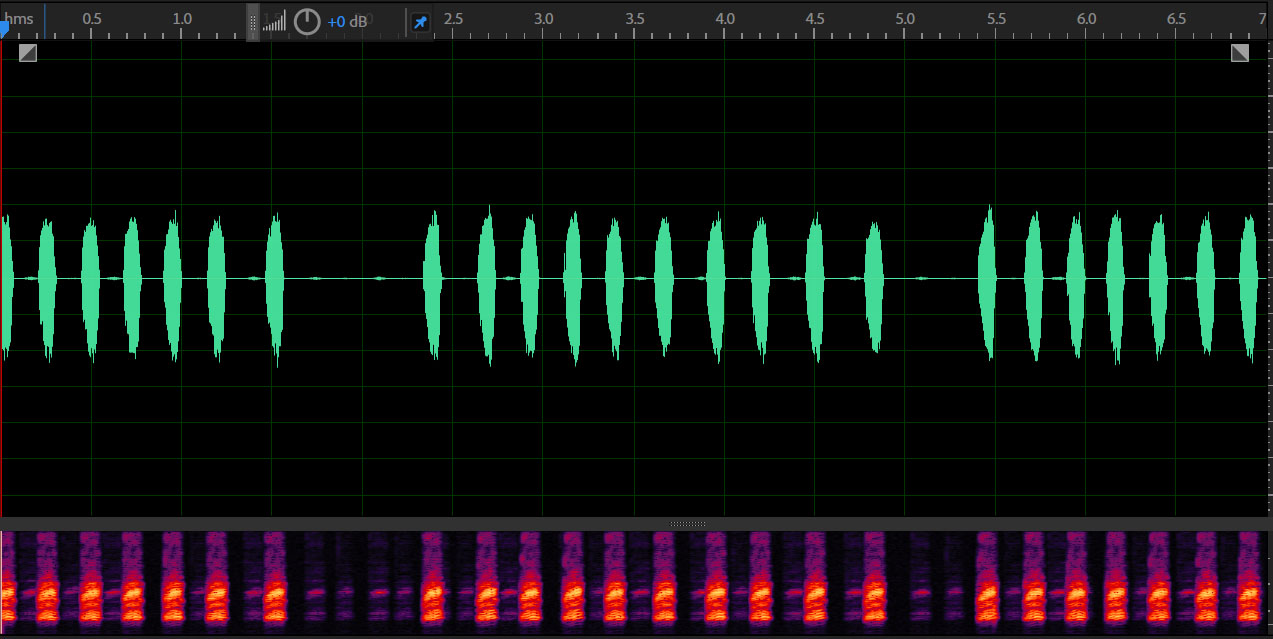
Spoken Dialogue System
Acquisition of OOV words through spoken dialogue (in Japanese)
The system detects out-of-vocabulary (OOV) words of his/her dictionary, and asks the user their properties.
The words, "農クレ(no:kure)" and "マリトッツォー(matritoqtso:)" are OOV words for the system in the demonstration.
Audio Signal Processing
Joint Separation and Localization of Moving Sound Sources Based on Neural Full-Rank Spatial Covariance Analysis
Please go to Yoshiaki's page
Real-time mask-based signal enhancement based on DNN using directional information
Real-time sound source localization based on DNN
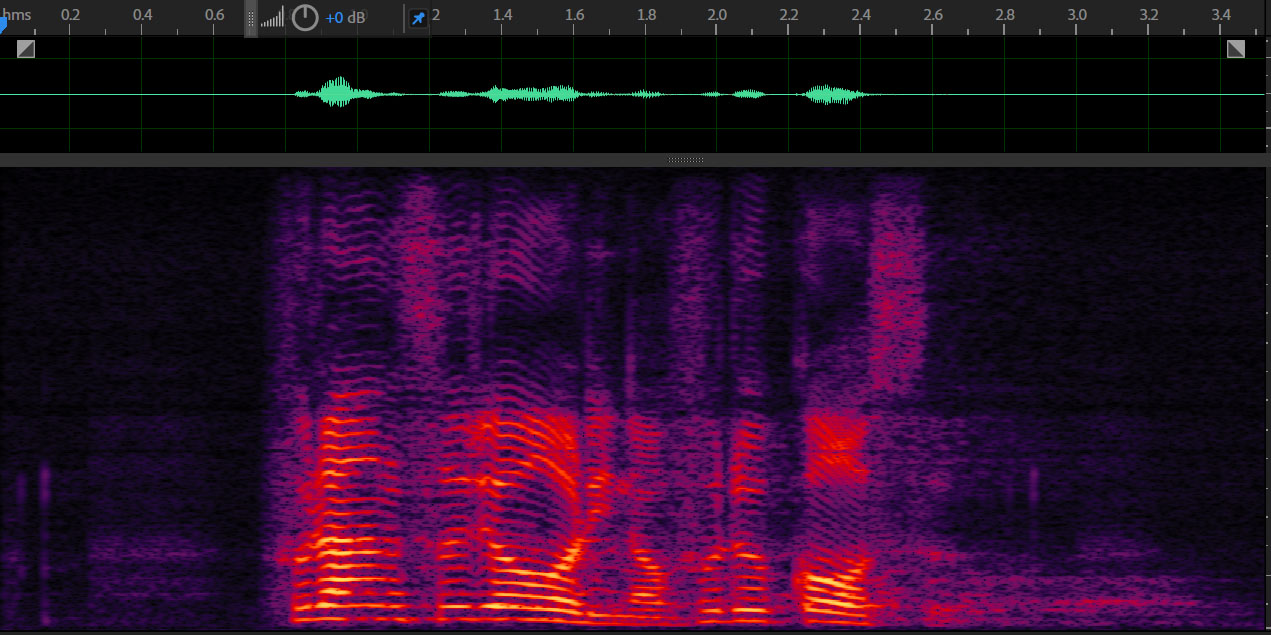
Blind Dereverberation using ICA
Observation
(1st ch of 4ch)
(1st ch of 4ch)
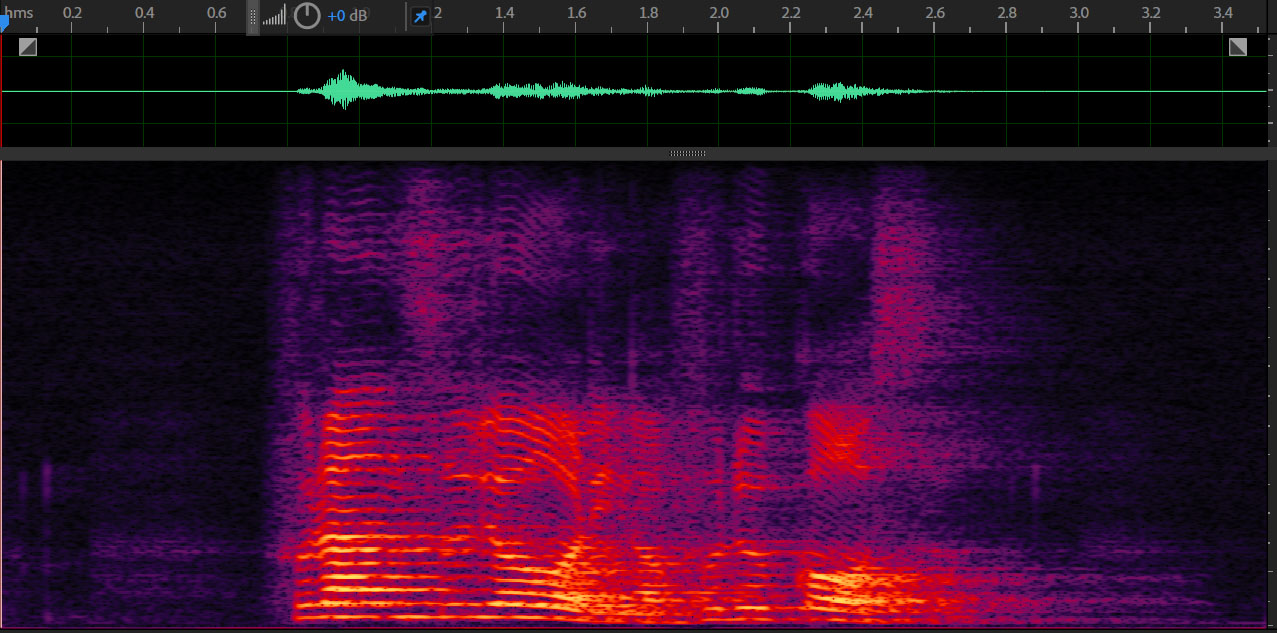
Dereverbed
Blind Source Separation using ICA
Observation
(1st ch of 8ch)
(1st ch of 8ch)
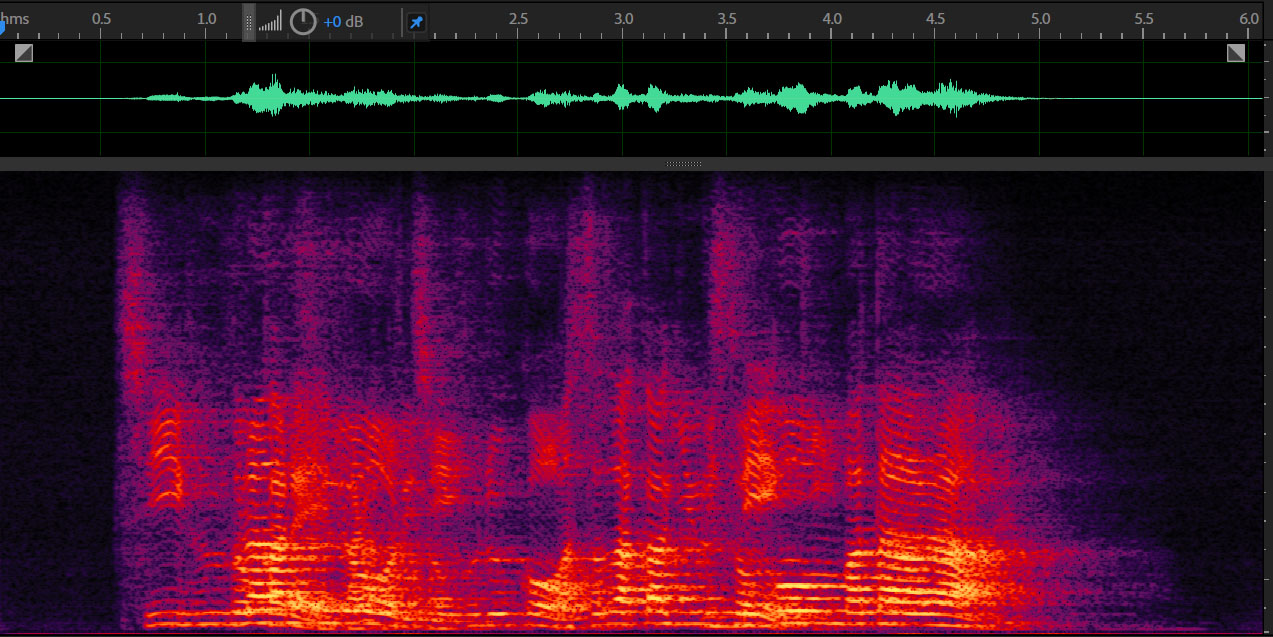
Separated signal 1
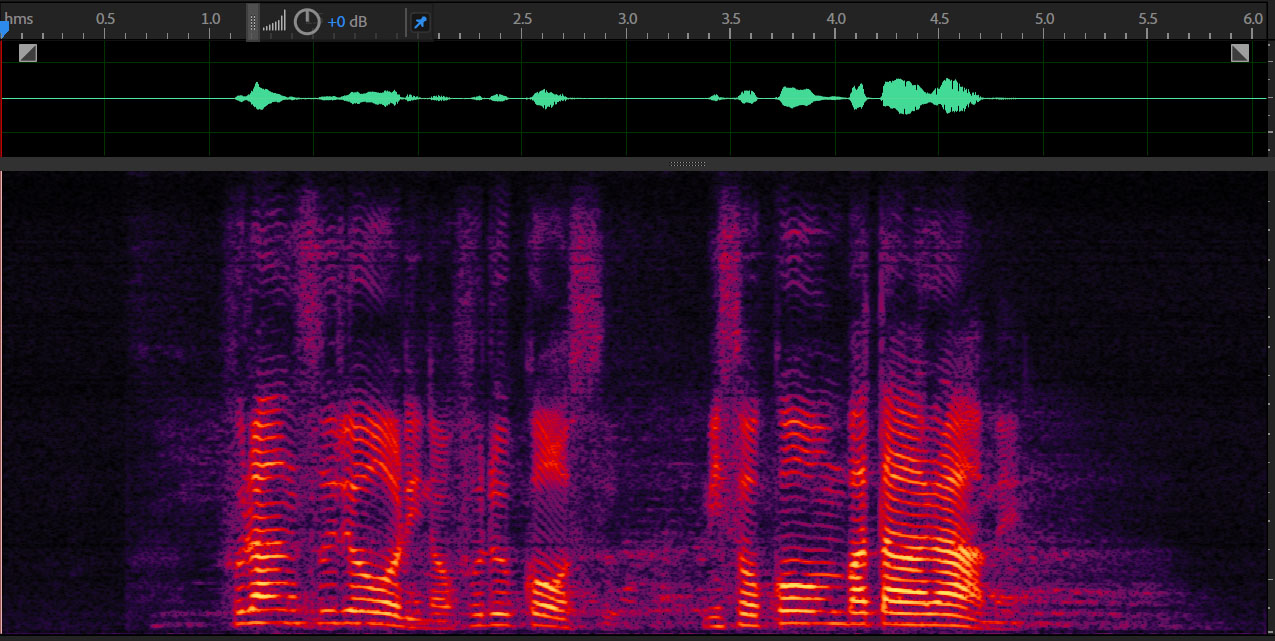
Separated signal 2
Frog Speech Anaysis (Separation)
Observation (2nd ch of 3ch)
Frog A
Frog B
Frog C
Framework
HARK
© 2016 Ryu Takeda
For undergraduates
研究室に興味のある学生の方へ.音声を使った簡単な実験はすぐに実行できます.
自分の音声を録音し, 波形をプロットしてみましょう.
Samples にあるプログラムを実行し, 出力された音声ファイルを聞いてみましょう.
フリーソフトで音声認識のカスタマイズも試せます.
Python 辺りに使い慣れておくと, 音声認識結果などのテキスト処理をする上でも色々と楽です.
なお, プログラミングスキルは情報系で不可欠なので, 色々とやってみることをお勧めします.
様々な経験(失敗)は早めにしておきましょう.
Softwares(ソフトウェア)
- vmware/virtual box: 仮想マシン上に Linux 環境を構築する際に必要.
- wavesurfer/audacity : 音声の録音・スペクトルグラムの表示が可. マルチチャネルファイルも扱える.
- Octave : 数値計算. グラフプロットなどが簡単. GUI も付属.
- Python (numpy, scipy, matplotlib) : 同上.
- OpenCV (C++, python): 画像処理用ライブラリ. 手軽に動画・画像を扱える.
- Julius: 音声認識ソフトウェア. Dictation kit を用いればすぐに音声認識を試せる.
- Eel (python): ローカルでの html ベース GUI 構築に便利. シンプルでデモなどに使いやすい.
References for training(学習用参考文献)
- MIT HRTF ( http://sound.media.mit.edu/resources/KEMAR.html ): 頭部伝達関数
- 言語処理100本ノック ( http://www.cl.ecei.tohoku.ac.jp/nlp100/ ): 乾・岡崎研究室
- フリーソフトでつくる音声認識システム
- パターン認識と機械学習 上/下
- 続・わかりやすいパターン認識
- 知の体力(新書)
Samples
- Released under the MIT license. Use for research, academic and educational purposes.
- 興味のある学生の方は仮想マシンに ubuntu をインストールして試してみてください.
- *.tar.gz ファイルは, ターミナル上で "tar zxvf [ファイル名]" と打つことで展開できます.
音声入力による単純な応答システム
予め登録している(単語, 応答文のペア)を用いて, 発話に含まれる単語から応答文を選択して出力.- Procedure
- Julius dictation kit を起動. (マイクは接続済みを仮定)
- 音声認識結果を受け取り, 認識単語から応答文を選択
- 出力
- Attention
- Julius dictation kit は別途用意. Linux 上での実行がベスト.
- 最小限の構成で作り込んではない.
sample code (python)
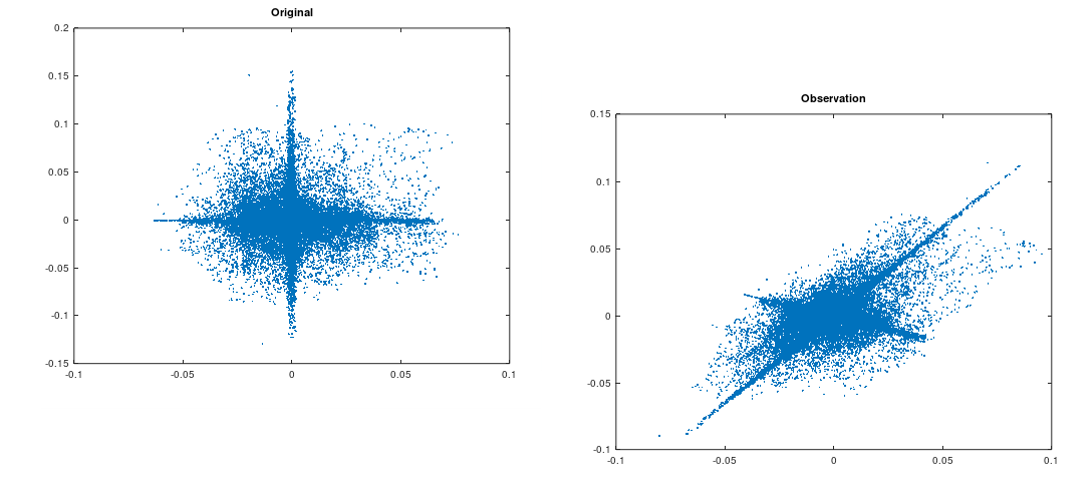
Independent Component Analysis for instantaneous mixture
瞬時混合モデルに基づく音源分離のサンプル
sample code (Octave)
- Procedure
- 2つの音声信号を瞬時混合, 観測音声の保存 (obs.wav)
- 白色化とICA を適用し分離
- 散布図のプロット, 分離音声の保存 (ica*.wav)
sample code (Octave)
Frequency-domain ICA for convolutive mixtures
周波数領域での瞬時混合モデルに基づく音源分離のサンプル- Procedure
- 2つの音声信号を畳み込み混合, 観測音声の保存 (obs*.wav)
- Frequency-domain ICA を適用し分離
- Time-domain 瞬時混合 ICA を適用し分離
- 散布図のプロット, 各種分離音声の保存 (fd-ica*.wav, td-ica*.wav)
- Attention
- パーミュテーションは解いていないので注意. 同梱データは解く必要なく揃う.
- 帯域毎の分離誤差とパーミュテーション誤差は分けて考えること.
sample code (Octave)
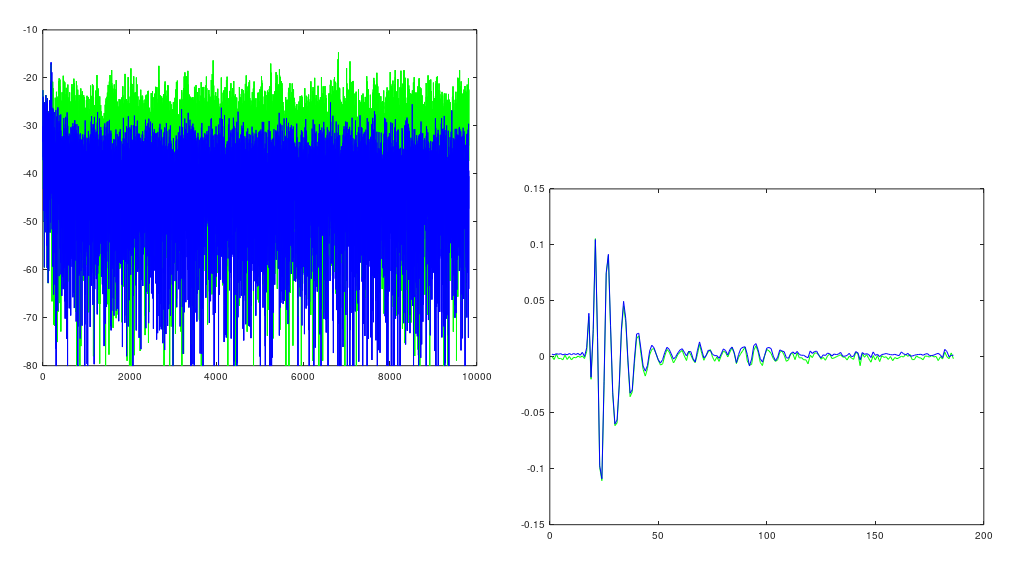
Adaptive Filter
基本的な適応フィルタのサンプル
sample code (Octave)
- Procedure
- 白色雑音, 音声にインパルス応答を畳みこみ
- LMS, NLMS, RLS, Kalman Filter でフィルタ推定
- 誤差等のプロット
sample code (Octave)
Shared library
動的にリンクする共有ライブラリ実装のサンプル.- Procedure
- dlopen, dlsym, dlclose を利用
sample code (C/C++)
Matrix vector multiplication using SSSE
行列・ベクトル積のSSSE命令による実装のサンプル. 8-bit 16変数の積和を数命令で行う.- Attention
- ベクトルの値は[0 1]に収まっていると仮定
- メモリアライメントを揃える必要がある (posix_memalign)
- Procedure
- 行列の値を行で正規化し, 8-bit signed char に変換
- ベクトルの値を 8-bit unsigned char に変換
- 16変数毎に ssse 命令で積和を計算・加算し, 最後に結果のスケールを調整
sample code (C/C++)
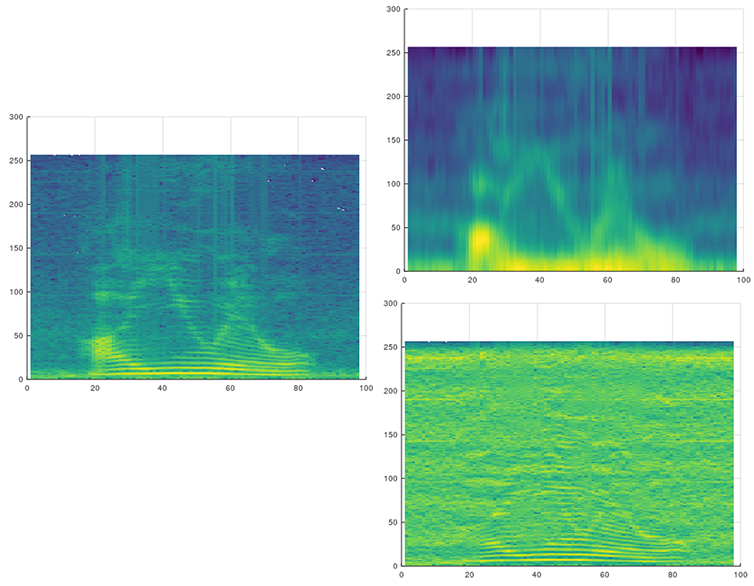
Cepstrum analysis
音声信号のケプストラム分析のサンプル.
sample code (Octave)
- Procedure
- 音声ファイル(aiueo.wav)を読み込み
- ケプストラム分析により, パワースペクトルを包絡成分と微細成分に分離
- パワースペクトル、包絡成分等をプロット
sample code (Octave)
Vowel classification
母音識別のサンプル.- Procedure
- 学習に用いる母音毎の音声ファイル(a_01.wav, ...)を読み込み、特徴量抽出
- 簡易な3層ニューラルネットワークのパラメータを学習
- 評価用の音声ファイル(aiueo_01.wav)に対して予測
- 学習データ、事後確率、識別結果等をプロット
sample code (Octave)
Infinite GMM
Infinite GMM 実装のサンプル.
sample code (python3)
- Procedure
- 2次元散布データを読み込み
- iGMM で Gibbs Sampling
- 各反復毎に分布をプロット
- numpy, scipy, matplotlib 等のインストールが必要
sample code (python3)
Unsupervised Word Segmentation
教師なし単語分割のシンプルな実装のサンプル.
sample exe. file (C/C++)
- Attention
- Ubuntu 16.04 or 17.10 (64bit) 用の実行ファイル.
仮想マシン上で作成. - 文字・単語 N-gram モデルともに Hierarchical Pitman-Yor language model のみの構成
- yaml-cpp (バージョン違いは symbolic link で対応を), python3, nkf 等のインストールが必要
sample exe. file (C/C++)
Useful Tools
KaldiHTK
Open FST
Mecab
palmkit
yaml-cpp
Eel
© 2016 Ryu Takeda
Stats
Journal/Conference Information
Main conferences for our research
Journal Papers
First
- 武田 龍, 駒谷 和範, 中島 圭祐, 中野 幹生: "複数の対話システムコンペティションにおけるシステム開発の設計指針", 人工知能学会論文誌, Vol.37, No.3, p.IDS-B_1-9, 2022.
- Ryu Takeda, Kazuhiro Nakadai and Kazunori Komatani: "Acoustic Model Training based on Node-wise Weight Boundary Model for Fast and Small-footprint Deep Neural Networks," Computer Speech & Language, Vol.46, pp.461-480, 2017.
- Ryu Takeda and Kazunori Komatani: "Noise-robust MUSIC-based Sound Source Localization using Steering Vector Transformation for Small Humanoids," Journal of Robotics and Mechatronics, Vol.29, No.1, pp.26-36, 2017.
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Efficient Blind Dereverberation and Echo Cancellation based on Independent Component Analysis for Actual Acoustic Signals," Neural Computation, Vol.24, Issue 1, pp.234-272, 2012.
- 武田 龍, 中臺 一博, 高橋 徹, 駒谷 和範, 尾形 哲也, 奥乃 博: "残響下でのバージイン発話認識のための多入力独立成分分析を応用したロボット聴覚", 日本ロボット学会誌, Vol.27, No.7, pp.782-792, 2009.
- 武田 龍, 中臺 一博, 駒谷 和範, 尾形 哲也, 奥乃 博: "独立成分分析に基づく適応フィルタのロボット聴覚への応用", 日本ロボット学会誌, Vol.26, No.6, pp.529-536, 2008.
Co-author
- 大塩 幹, 武田 龍, 駒谷 和範: "ユーザ返答パターンを用いた音節列と単語境界の同時推定に基づく音声対話中の未知語認識", 電子情報通信学会論文誌, Vol.J108-D, No.4, pp.128-137, Apr., 2025.
- Hokuto Munakata, Yoshiaki Bando, Ryu Takeda, Kazunori Komatani and Masaki Onishi: "Joint Separation and Localization of Moving Sound Sources Based on Neural Full-Rank Spatial Covariance Analysis," IEEE Signal Processing Letters, Vol.30, pp.384-388, April, 2023. IEEE Xplore
- Kazunori Komatani, Kohei Ono, Ryu Takeda, Eric Nichols, Mikio Nakano: "User Impressions of System Questions to Acquire Lexical Knowledge during Dialogues," Dialogue & Discourse, Vol.13, No. 1, pp.96-122, 2022.
- 大野 航平, 武田 龍, ニコルズ エリック, 中野 幹生, 駒谷 和範: "対話を通じた未知語のクラス獲得に向けた暗黙的確認の提案", 人工知能学会論文誌, Vol.33, No.1, pp. DSH-E_1-10, 2018. J-stage
- Ikkyu Aihara, Ryu Takeda, Takeshi Mizumoto, Takuma Otsuka, Hiroshi G. Okuno: "Size Effect on Call Properties of Japanese Tree Frogs Revealed by Audio-Processing Technique," Journal of Robotics and Mechatronics, Vol.29, No.1, pp.247-254, 2017.
- Masahito Togami, Yohei Kawaguchi, Ryu Takeda, Yasunari Obuchi and Nobuo Nukaga: "Optimized speech dereverberation from probabilistic perspective for time varying acoustic transfer function," IEEE Transactions on Audio, Speech, and Language Processing, Vol.21, Issue 7, pp.1369-1380, 2013. IEEE Xplore
- Yasunari Obuchi, Ryu Takeda, Masahito Togami: "Noise suppression method for preprocessor of time-lag speech recognition system based on bidirectional optimally modified log spectral amplitude estimation," Acoustical Science and Technology, Vol.34, No.2, pp.133-141, 2013.
- Ikkyu Aihara, Ryu Takeda, Takeshi Mizumoto, Takuma Otsuka, Toru Takahashi, Hiroshi G. Okuno, Kazuyuki Aihara: "Complex and transitive synchronization in a frustrated system of calling frogs," Physical Review E, Vol.83, Issue 3, pp.031913 [5 pages], 2011.
- 駒谷 和範, 松山 匡子, 武田 龍, 高橋 徹, 尾形 哲也, 奥乃 博: "発語行為レベルの情報をユーザ発話の解釈に用いる音声対話システム", 情報処理学会論文誌, Vol.52, No.12, pp.3374-3385, 2011. IPSJ
- Takeshi Mizumoto, Ikkyu Aihara, Takuma Otsuka, Ryu Takeda, Kazuyuki Aihara, Hiroshi G. Okuno: "Sound Imaging of Nocturnal Animal Calls in Their Natural Habitat," Journal of Comparative Physiology A, Vol.197, No.9, pp.915-921, 2011. doi:10.1007/s00359-011-0652-7
- 村田 和真, 中臺 一博, 武田 龍, 奥乃 博, 長谷川 雄二, 辻野 広司: "ロボットを対象としたビートトラッキングロボットの提案とその音楽ロボットへの応用", 日本ロボット学会誌, Vol.27, No.7, pp.793-801, 2009. J-stage
- 山本 俊一, 中臺 一博, 中野幹生, 辻野 広司, Jean-Marc Valin, 武田 龍, 駒谷 和範, 尾形 哲也, 奥乃 博: "遺伝的アルゴリズムを用いたパラメータ最適化による話者位置に基づく同時発話認識の向上", ヒューマンインタフェース学会論文誌, Vol.8, No.2, pp.203-212, 2006.
Peer-Reviewed International Conference Papers
First
- Ryu Takeda and Kazunori Komatani: "Reducing Orthographic Dependency on Paired Data by Probabilistic Integration via Syllabogram for Japanese Dialogue Speech Recognition," Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.549-554, Oct., 2025.
- Ryu Takeda and Kazunori Komatani: "Scale-invariant Online Voice Activity Detection under Various Environments," Proceedings of Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.397-402, Nov., 2024.
- Ryu Takeda and Kazunori Komatani: "Toward OOV-word Acquisition during Spoken Dialogue using Syllable-based ASR and Word Segmentation," International Workshop on Spoken Dialogue Systems Technology, Mar., 2024.
- Ryu Takeda, Hokuto Munakata and Kazunori Komatani: "Link Prediction Based on Large Language Model and Knowledge Graph Retrieval under Open-World and Resource-Restricted Environment," International Joint Conference on Knowledge Graphs, Dec. 9, 2023.
- Ryu Takeda, Yui Sudo and Kazunori Komatani: "Flexible Evidence Model to Reduce Uncertainty Mismatch Between Speech Enhancement and ASR Based on Encoder-Decoder Architecture," Proceedings of Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.1830-1837, Nov. 2, 2023. [74% (395/532): Regular 69%, Special 79%]
- Ryu Takeda, Yui Sudo, Kazuhiro Nakadai and Kazunori Komatani: "Empirical Sampling from Latent Utterance-wise Evidence Model for Missing Data ASR based on Neural Encoder-Decoder Model," Proceedings of Interspeech, pp.3789-3793, Sep. 21, 2022. [51.5% (1102/2140)]
- Ryu Takeda, Kazuhiro Nakadai and Kazunori Komatani: "Spatial Normalization to Reduce Positional Complexity in Direction-aided Supervised Binaural Sound Source Separation," Proceedings of Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.248-253, Dec. 15, 2021. [67.5% (182/?)]
- Ryu Takeda and Kazunori Komatani: "Age Estimation with Speech-age Model for Heterogeneous Speech Datasets," Proceedings of Interspeech, pp.4164-4168, Sep. 3, 2021. [48.4% (963/1990)]
- Ryu Takeda and Kazunori Komatani: "Frame-wise Online Unsupervised Adaptation of DNN-HMM Acoustic Model from Perspective of Robust Adaptive Filtering," Proceedings of Interspeech, pp.1291-1295, Oct. 26, 2020. [47.8% (1024/2141)]
- Ryu Takeda and Kazunori Komatani: "Attribute Prediction of Unknown Lexical Entities based on Mixture of Bayesian Segmentation Model," Life Long Learning for Spoken Language Systems Workshop, 7 pages, Dec. 14, 2019.
- Ryu Takeda, Kazunori Komatani and Alexandar I. Rudnicky: "Word Segmentation from Phoneme Sequences based on Pitman-Yor Semi-Markov Model Exploiting Subword Information," Proceedings of IEEE Workshop on Spoken Language Technology (SLT), pp.763-770, Dec. 20, 2018. [58.4% (150/257)] IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai and Kazunori Komatani: "Multi-timescale Feature-extraction Architecture of Deep Neural Networks for Acoustic Model Training from Raw Speech Signal," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and System (IROS), pp.2508-2510, Oct. 2, 2018. [46.7% (1257/2693)] IEEE Xplore Scopus
- Ryu Takeda, Yoshiki Kudo, Kazuki Takashima, Yoshifumi Kitamura and Kazunori Komatani: "Unsupervised Adaptation of Neural Networks for Discriminative Sound Source Localization with Eliminative Constraint," Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.3514-3518, April 20, 2018. [49.7 % (1406/2830)] IEEE Xplore Scopus
- Ryu Takeda and Kazunori Komatani: "Unsupervised Segmentation of Phoneme Sequences based on Pitman-Yor Semi-Markov Model using Phoneme Length Context," Proceedings of The 8th International Joint Conference on Natural Language Processing (IJCNLP), pp.243-252 (long paper), Nov. 28, 2017. [30.9% (179/580)]
- Ryu Takeda, Kazuhiro Nakadai and Kazunori Komatani: "Node pruning based on Entropy of Weights and Node Activity for Small-footprint Acoustic Model based on Deep Neural Networks," Proceedings of Interspeech, pp.1636-1640, Aug. 22, 2017. [52.3 % (799/1528)] Scopus
- Ryu Takeda and Kazunori Komatani: "Unsupervised Adaptation of Deep Neural Networks for Sound Source Localization using Entropy Minimization," Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.2217-2221, Mar. 7, 2017. [48.5% (1220/2518)]. IEEE Xplore Scopus
- Ryu Takeda and Kazunori Komatani: "Bayesian Language Model based on Mixture of Segmental Contexts for Spontaneous Utterances with Unexpected Words," Proceedings of International Conference on Computational Linguistics (COLING), pp.161-170, Dec. 13, 2016. [32.4% (337/1039)] Scopus
- Ryu Takeda and Kazunori Komatani: "Discriminative Multiple Sound Source Localization based on Deep Neural Networks using Independent Location Model," Proceedings of IEEE Workshop on Spoken Language Technology (SLT), pp.603-609, Dec. 16, 2016. [60.9% (89/148):regular paper]. IEEE Xplore Scopus
- Ryu Takeda and Kazunori Komatani: "Sound Source Localization based on Deep Neural Networks with Directional Activate Function Exploiting Phase Information," Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.405-409, Mar. 23, 2016. [47.1% (1265/2682)]. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai and Kazunori Komatani: "Acoustic Model Training based on Node-wise Weight Boundary Model Increasing Speed of Discrete Neural Networks," Proceedings of IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp.52-58, Dec. 14, 2015. [47.8% (107/224)]. IEEE Xplore Scopus
- Ryu Takeda and Kazunori Komatani: "Performance comparison of MUSIC-based sound localization methods on small humanoid under low SNR conditions," Proceedings of IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), pp.859--865, Nov. 4, 2015. IEEE Xplore Scopus
- Ryu Takeda, Naoyuki Kanda and Nobuo Nukaga: "Boundary contraction training for acoustic models based on discrete deep neural networks," Proceeding of Interspeech, pp.1063-1067, 2014. [52.3% (614/1173)] Scopus
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Speedup and Performance Improvement of ICA-based Robot Audition by Parallel and Resampling-based Block-wise Processing", Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.1949-1956, IEEE, RSJ, Taipei, 18-22 Oct. 2010. [49.1%]. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Upper-limit Evaluation of a Robot Audition based on ICA-BSS in Multi-source, Barge-in and Highly Reveberant Conditions," Proceedings of IEEE-RAS International Conference on Robotics and Automation (ICRA), pp.4366-4371, May 3-8, 2010, Anchorage, Aalaska, USA. [41.0% (847/2062)]. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Automatic Estimation of Reverberation Time with Robot Speech to Improve ICA-based Robot Audition," Proceedings of IEEE-RAS Interanational Conference on Humanoid Robots (Humanoids), pp.250-355, IEEE, Paris, Dec. 7-10, 2009. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Step-size Parameter Adaptation of Multi-channel Semi-blind ICA with Piecewise Linear Model for Barge-in-able Robot Audition," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp.2273-2282, IEEE, RSJ, St. Louis, 11-15 Oct. 2009. [54.5% (900/1650)]. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Toru Takahashi, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "ICA-based Efficient Blind Dereverberation and Echo Cancellation Method for Barge-in-able Robot Audition," Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp.3677-3680, Taipei, Taiwan, April 19 - April 24, 2009. [44.7% (1178/2633)] ((財)電気通信普及財団海外渡航助成). IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Barge-in-able Robot Audition Based on ICA and Missing Feature Theory under Semi-Blind Situation," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp.1718-1723, IEEE/RSJ, Nice, Sept. 2008. IEEE Xplore Scopus
- Ryu Takeda, Kazuhiro Nakadai, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Exploiting Known Sound Sources to Improve ICA-based Robot Audition in Speech Separation and Recognition," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp.1757--1762, San Diego, Oct. 2007. IEEE Xplore Scopus
- Ryu Takeda, Shun'ichi Yamamoto, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Evaluation of Two Simultaneous Continous Speech Recognition with ICA BSS and MTF-based ASR," New Trends in Applied Artificial Intelligence (IEA/AIE), LNAI 4570, pp.384-394, Springer-Verlag. Kyoto, Jun. 2007. Socopus
- Ryu Takeda, Shun'ichi Yamamoto, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Missing-Feature based Speech Recognition for Two Simultaneous Speech Signals Separated by ICA with a pair of Humanoid Ears," Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp.878--885, Beijing, China, Sep. 2006. (IEEE Robotics and Automation Chapter, Japan 支部Young Award 受賞, RSJ/SICE AWARD for IROS2006 Best Paper Nomination Finalist) IEEE Xplore Scopus
- Ryu Takeda, Shun'ichi Yamamoto, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Improving Speech Recognition of Two simultaneous Speech Signals by Integrating ICA BSS and Automatic Missing Feature Mask Generation," Proceedings of International Conference on Spoken Language Processing (ICSLP/Interspeech), pp. 2302-2305, Pittsburgh, Sep. 2006. ((財) 原総合知的通信システム基金 国際会議論文発表助成). Scopus
Co-author
- Daichi Yukizawa, Kenta Yamamoto, Ryu Takeda, Kazunori Komatani: "Estimating User Sentiment at Sub-exchange Granularity from Exchange-level Annotations," Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.855-860, Oct., 2025.
- Issei Waki, Ryu Takeda, Kazunori Komatani:: "Learning to Ask Efficiently in Dialogue: Reinforcement Learning Extensions for Stream-based Active Learning," Proceedings of Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), pp.309–317, May, 2025.
- Yunosuke Kubo, Ryo Yanagimoto, Mikio Nakano, Kenta Yamamoto, Ryu Takeda, Kazunori Komatani:: "Developing Classifiers for Affirmative and Negative User Responses with Limited Target Domain Data for Dialogue System Development Tools," Proceedings of International Workshop on Spoken Dialogue Systems (IWSDS), pp.309–317, May, 2025.
- Kenta Yamamoto, Ryu Takeda, Kazunori Komatani: "Analysis of Voice Activity Detection Errors in API-based Streaming ASR for Human-Robot Dialogue," Proceedings of International Workshop on Spoken Dialogue Systems (IWSDS), pp.245-253, May, 2025.
- Shun Katada, Ryu Takeda and Kazunori Komatani: "Collecting Human-Agent Dialogue Dataset with Frontal Brain Signal toward Capturing Unexpressed Sentiment," Proceedings of Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pp.3518-3528, Torino, Italia, May, 2024.
- Miki Oshio, Hokuto Munakata, Ryu Takeda and Kazunori Komatani: "Out-Of-Vocabulary Word Detection in Spoken Dialogues Based on Joint Decoding with User Response Patterns," Proceedings of Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.1753-1759, 2023.
- Shuichi Chikatsuji, Kenta Yamamoto, Ryu Takeda and Kazunori Komatani: "Knowledge Graph Augmentation with Entity Identification for Improving Knowledge Graph Completion Performance," Proceedings of Pacific Rim International Conference on Artificial Intelligence (PRICAI), pp.480-487, 2023. [31.0% (131/422)] (short paper)
- Kazunori Komatani, Ryu Takeda and Shogo Okada: "Analyzing Differences in Subjective Annotations by Participants and Third-party Annotators in Multimodal Dialogue Corpus," Proceedings of Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), pp.104-113, 2023. [45.5% (overall)]
- Hokuto Munakata, Ryu Takeda and Kazunori Komatani: "Recursive Sound Source Separation with Deep Learning-based Beamforming for Unknown Number of Sources," Proceedings of Interspeech, pp.1688-1692, Dublin, Ireland, Aug., 2023. [49.7%]
- Zhi Li, Ryu Takeda and Takahiro Hara: "Meta-domain Adversarial Contrastive Learning for Alleviating Individual Bias in Self-sentiment Predictions," Proceedings of Interspeech, pp.2428-2432, Dublin, Ireland, Aug., 2023. [49.7%]
- Hokuto Munakata, Ryu Takeda and Kazunori Komatani: "Training Data Generation with DOA-based Selecting and Remixing for Unsupervised Training of Deep Separation Models," Proceedings of Interspeech, pp.861--865, Sep. 19, 2022. [51.5% (1102/2140)]
- Hokuto Munakata, Ryu Takeda and Kazunori Komatani: "Multiple-Embedding Separation Networks: Sound Class-Specific Feature Extraction for Universal Sound Separation," Proceedings of 13th Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp.961-967, Dec. 15, 2021.
- Kazunori Komatani, Ryu Takeda, Keisuke Nakashima and Mikio Nakano: "Design guidelines for developing systems for dialogue system competitions," Proceedings of International Workshop on Spoken Dialogue Systems (IWSDS), 16 pages, Nov. 16, 2021.
- Kazuhiro Nakadai, Yosuke Fukumoto, Ryu Takeda: "Investigation of Node Pruning Criteria for Neural Networks Model Compression with Non-linear Function and Non-uniform Network Topology," Proceedings of IEEE Workshop on Spoken Language Technology (SLT), pp.117-124, Jan. 2021.
- Kazuaki Yamabe, Chihiro Suga, Teruhisa Misu, Ryu Takeda, Kazunori Komatani: "Predicting when drivers need AR navigation," Proceedings of The 8th Biennial Workshop on DSP for In-Vehicle and Mobile Systems, 7 pages, Oct. 9, 2018.
- Kohei Ono, Ryu Takeda, Eric Nichols, Mikio Nakano and Kazunori Komatani: "Lexical Acquisition through Implicit Confirmations over Multiple Dialogues," Proceedings of Annual SIGdial Meeting on Discourse and Dialogue (SIGDIAL), pp.50-59, Aug. 17, 2017. [40.9 % (47/115)]
- Kohei Ono, Ryu Takeda, Eric Nichols, Mikio Nakano and Kazunori Komatani: "Toward Lexical Acquisition during Dialogues through Implicit Confirmation for Closed-Domain Chatbots," Proceedings of Second Workshop on Chatbots and Conversational Agent Technologies (WOCHAT), 2016.
- Naoyuki Kanda, Ryu Takeda and Yasunari Obuchi: "Elastic spectral distortion for low resource speech recognition with deep neural networks," Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), pp.309-314, 2013. IEEE Xplore
- Naoyuki Kanda, Ryu Takeda and Yasunari Obuchi: "Noise robust speaker verification with delta cepstrum normalization," Proceedings of INTERSPEECH, pp.3112-3116, 2013.
- Yasunari Obuchi, Ryu Takeda and Naoyuki Kanda: "Voice activity detection based on augmented statistical noise suppression, Proceedings of Asia-Pacific Signal & Information Processing Association Annual Summit and Conference (APISPA), pp.1-4, 2012. IEEE Xplore
- Masahito Togami, Yohei Kawaguchi, Ryu Takeda, Yasunari Obuchi and Nobuo Nukaga: "Multichannel speech dereverberation and separation with optimized combination of linear and non-linear filtering," Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.4057-4060, 2012. IEEE Xplore
- Naoyuki Kanda, Ryu Takeda, Yasunari Obuchi: "Using rhythmic features for Japanese spoken term detection," Proceedings of IEEE Spoken Language Technology Workshop (SLT), pp.170-175, 2012. IEEE Xplore
- Takeshi Mizumoto, Kazuhiro Nakadai, Takami Yoshida, Ryu Takeda, Takuma Otsuka, Toru Takahashi, Hiroshi G. Okuno: "Design and implementation of selectable sound separation on the Texai telepresence system using HARK," Proceedings of IEEE International Conference on Robotics and Automation (ICRA) , pp.2130--2137, 2011. IEEE Xplore
- Yasunari Obuchi, Ryu Takeda and Masahito Togami: "Bidirectional OM-LSA speech estimator for noise robust speech recognition," Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), pp.173-178, 2011. IEEE Xplore
- Kyoko Matsuyama, Kazunori Komatani, Ryu Takeda, Toru Takahashi, Tetsuya Ogata, Hiroshi G. Okuno: "Analyzing User Utterances in Barge-in-able Spoken Dialogue System for Improving Identification Accuracy," Proceedings of International Conference on Spoken Language Processing (Interspeech), pp.3050--3053, 2010. (58.2%) Makuhari, 30 Sep.
- Ikkyu Aihara, Ryu Takeda, Takeshi Mizumoto, Takuma Otsuka, Toru Takahashi, Hiroshi G. Okuno: "Synchronization in Frustrated Calling Behavior of Japanese Tree Frogs," Conference on Dynamics in Systems Biology, Univ. of Aberdeen, UK, Sep. 16, 2009. (oral)
- Kazumasa Murata, Kazuhiro Nakadai, Kazuyoshi Yoshii, Ryu Takeda, Toyotaka Torii, Hiroshi G. Okuno, Yuji Hasegawa, Hiroshi Tsujino: "A Robot Uses Its Own Microphone to Synchronize Its Steps to Musical Beats While Scatting and Singing", Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.2459-2464, Nice, 24 Sep. 2008. (Award for Entertainment Robots and Systems (NTF Award) Nomination Finalist)
- Takeshi Mizumoto, Ryu Takeda, Kazuyoshi Yoshii, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "A Robot Listens to Music and Counts Its Beats Aloud by Separating Music from Counting Voice", Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.1538-1543, Nice, 24 Sep. 2008. (Award for Entertainment Robots and Systems (NTF Award) Nomination Finalist ). IEEE Xplore
- Kazumasa Murata, Kazuhiro Nakadai, Kazuyoshi Yoshii, Ryu Takeda, Toyotake Torii, Hiroshi G. Okuno, Yuji Hasegawa, Hiroshi Tsujino: "A Robot Singer with Music Recognition Based on Real-Time Beat Tracking", Proceedings of 9th International Conference on Musical Information Retreival (ISMIR), pp.199-204, Philadelphia, 15 Sep. 2008.
- Kazumasa Murata, Kazuhiro Nakadai, Ryu Takeda, Hiroshi G. Okuno, Toyotaka Torii, Yuji Hasegawa, Hiroshi Tsujino: "A Beat-Tracking Robot for Human-Robot Interaction and Its Evaluation", Proceedings of IEEE-RAS Interanational Conference on Humanoid Robots (Humanoids), pp.79-84, Daejeon, Korea, Dec. 2, 2008. IEEE Xplore
- Shun'ichi Yamamoto, Ryu Takeda, Kazuhiro Nakadai, Mikio Nakano, Hiroshi Tsujino, Jean-Marc Valin, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: “Recognition of Simultaneous Speech by Estimating Reliability of Separated Signals for Robot Audition”, PRICAI 2006: Trends in Artificial Intelligence, Lecture Note in Computatioal Science, No. 4099, pp.484-494, Springer-Verlag, Guilin, China, Aug. 2006
- Shun'ichi Yamamoto, Kazuhiro Nakadai, Mikio Nakano, Hiroshi Tsujino, Jean-Marc Valin, Ryu Takeda, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Genetic Algorithm based Improvement of Robot's Hearing Capabilities in Separating and Recognizing Simultaneous Speech Signals", Advances in Applied Artificial Intelligence (IEA/AIE), Lecture Note in Artificial Intelligence, No. 4031, pp.207-217, Springer-Verlag. Annecy, France, Jun. 2006.
- Shun'ichi Yamamoto, Ryu Takeda, Kazuhiro Nakadai, Mikio Nakano, Hiroshi Tsujino, Jean-Marc Valin, Kazunori Komatani, Tetsuya Ogata, Hiroshi G. Okuno: "Leak Energy based Missing Feature Mask Generation for ICA and GSS and Its Evaluation with Simultaneous Speech Recognition", Proceedings of ISCA Tutorial and Research Workshop on Statistical and Perceptual Audition (SAPA), pp.42-46, 2006
Review and Article
Co-author
- 山本 俊一, 武田 龍, 奥乃 博: "ミッシングフィーチャ理論に基づく音声認識を利用した複数話者同時発話認識", 計測と制御, Vol.46, No.6, pp.447-452, 2007.
- 合原 一究, 武田 龍, 水本 武志, 高橋 徹, 奥乃 博: "ニホンアマガエルの同期した発声行動に関する数理的研究および音響信号解析", 数理解析講究録, 1663, pp.153-158, 2009.
Domestic Meeting Papers/Presentations
First
- 武田 龍, 中臺一博, 駒谷和範:"量子化 Deep Neural Network のための有界重みモデルに基づく音響モデル学習", 第46回 AIチャレンジ研究会, Nov. 2016.
- 武田 龍, 駒谷和範:"方向依存活性化関数を用いたDeep Neural Network に基づく識別的音源定位", 第112回音声言語情報処理研究会, July 2016. (情報処理学会 山下記念研究賞)
- 武田 龍: "独立成分分析と雑音下音声認識技術によるロボット聴覚", 京都大学ICTイノベーション2009, 2009年2月20日
- 武田 龍, 中臺 一博, 高橋 徹, 駒谷 和範, 尾形 哲也, 奥乃 博 :"独立成分分析を応用したロボット聴覚による残響下におけるバージイン発話認識", 日本ロボット学会第26回学術講演会, 1A2-02, Sept. 2008.
- 武田 龍, 中臺 一博, 駒谷 和範, 尾形 哲也, 奥乃 博:"ロボット音声対話のためのMFTとICAによるバージイン許容機能の評価", 情報処理学会第70回全国大会, 3U-1, Mar. 2008.
- 武田 龍, 中臺 一博, 駒谷 和範, 尾形 哲也, 奥乃 博 :"独立成分分析に基づく適応フィルタのロボット聴覚への応用", 日本ロボット学会第25回大会, 1N6 , Sept. 2007.
- 武田 龍, 山本 俊一, 駒谷 和範, 尾形 哲也, 奥乃 博 :"ICA と MFT に基づく音声認識における Soft Mask を用いた性能評価", 情報処理学会第69回全国大会, 6ZB-6, Mar. 2007.
- 武田 龍, 山本 俊一, 駒谷 和範, 尾形 哲也, 奥乃 博 :"ICAとミッシングフィーチャマスク自動生成によるロボット聴覚", 日本ロボット学会第24回大会, 1B13, Sept. 2006.
- 武田 龍, 山本 俊一, 駒谷 和範, 尾形 哲也, 奥乃 博 :"ICA による音源分離とミッシングフィーチャマスクの自動生成による同時発話認識", 情報処理学会第68回全国大会, March 2006.
Co-author
- 大谷 蒼太,武田 龍,駒谷 和範: "加齢性難聴に対する音声明瞭度改善を目的とした声質変換の有効性検証".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.(学生奨励賞受賞)
- 石森 大路,武田 龍,駒谷 和範: "音声サンプルを用いた対象話者を除外可能な発話区間検出".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.(学生奨励賞受賞)
- 近辻 脩壱,武田 龍,駒谷 和範: "知識グラフ補完のためのトリプル選択を用いたデータ拡充".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.
- 脇 一晟,武田 龍,駒谷 和範: "新語抽出のストリーム型能動学習における半教師あり学習によるサンプル効率の向上".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.
- 大塩 幹,武田 龍,駒谷 和範: "音節列からの未知語検出のための単語N-gram確率を用いた過分割抑制".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.(学生奨励賞受賞)
- 雪澤 大地,山本 賢太,武田 龍,駒谷 和範: "音声対話システムにおける交換内部でのマルチモーダル心象推定".情報処理学会全国大会. 立命館大学 大阪いばらきキャンパス. Mar., 2025.
- 古川 温馬, 武田 龍, 本田 剛己, 合原 一究, 青柳 富誌生: "様々な音声刺激に対するカエルの発声行動の位相振動子による解析". 日本物理学会年次大会, 北海道大学, Sep., 2024.
- 平川 巧人,大塩 幹,近辻 脩壱,武田 龍,駒谷 和範: "誤りを含む音節認識結果に対応する知識グラフ内エンティティの同定". 情報処理学会全国大会, 神奈川大学, Mar., 2024.
- 峯瀬 平,堅田 俊,羅 兆傑,武田 龍,駒谷 和範: "異なる収録環境での対話音声に対する心象推定のためのL1距離に基づく特徴選択". 情報処理学会全国大会, 神奈川大学, Mar., 2024.
- 大塩 幹,武田 龍,駒谷 和範: "未知語認識機能を有する音声対話システムの構築とデータ収集". 情報処理学会全国大会, 神奈川大学, Mar., 2024. (学生奨励賞受賞)
- 久保 裕之輔,柳元 涼,山本 賢太,中野 幹生,武田 龍,駒谷 和範: "対話ロボットコンペティションのためのユーザ応答に対する肯定否定判定器の開発".情報処理学会全国大会, 神奈川大学, Mar., 2024.
- 堀口 勇輝,山本 賢太,武田 龍,駒谷 和範: "特定ドメインの対話システムにおける発話矛盾検出のための前提文生成". 情報処理学会全国大会, 神奈川大学, Mar., 2024.
- 脇 一晟,堅田 俊,武田 龍,駒谷和範: "新語を含む単語分割のためのストリーム型能動学習における獲得関数の強化学習". 情報処理学会全国大会, 神奈川大学, Mar., 2024.(学生奨励賞受賞)
- 柳元 涼,山本 賢太,武田 龍,駒谷 和範: "ユーザの性別・年齢・性格特性に基づくマルチモーダル心象推定". 情報処理学会全国大会, 神奈川大学, Mar., 2024.(学生奨励賞受賞)
- 久保 祐喜, 羅 兆傑, 武田 龍, 駒谷 和範: "マルチモーダル対話におけるクロスコーパスでの心象推定のための特徴量選択", 情報処理学会第85回全国大会, Mar. 4, 2023. (学生奨励賞受賞)
- 久保 裕之輔, 羅 兆傑, 武田 龍, 駒谷 和範: "マルチモーダル対話におけるユーザごとの心象推定のための学習データの割当て", 情報処理学会第85回全国大会, Mar. 4, 2023.
- 生嶋 竜実, 武田 龍, 合原 一究, 駒谷 和範: "カエルの合唱音声に対する教師ありモノラル音源分離のための音声合成によるデータ拡張", 情報処理学会第85回全国大会, Mar. 3, 2023
- 宗像 北斗, 坂東 宜昭, 武田 龍, 駒谷 和範, 大西 正輝: "音源定位・分離の同時学習に基づく移動音源の深層ブラインド音源分離", 情報処理学会第85回全国大会, Mar. 3, 2023. (学生奨励賞受賞)
- 近辻 脩壱, 宗像 北斗, 武田 龍, 駒谷 和範: "知識グラフ補完性能向上のための同一エンティティ判定を用いた知識グラフ拡充", 情報処理学会第85回全国大会, Mar. 3, 2023. (学生奨励賞受賞)
- 大塩 幹, 宗像 北斗, 武田 龍, 駒谷 和範: "対話中のユーザの返答パターンに基づく音声発話中の未知語認識", 情報処理学会第85回全国大会, Mar. 3, 2023. (学生奨励賞受賞)
- 駒谷 和範, 武田 龍, 岡田 将吾: "マルチモーダル対話コーパスに対する主観的アノテーション結果に関する分析", 第96回 言語・音声理解と対話処理研究会(第13回対話システムシンポジウム), pp.181-186, Dec. 14, 2022.
- 谷口 琉聖, 武田 龍, 駒谷 和範, 翠 輝久, 細見 直希, 山田 健太郎: "物体検出器により得た確信度が対話システム性能に与える影響", 第96回 言語・音声理解と対話処理研究会(第13回対話システムシンポジウム), pp.63-68, Dec. 13, 2022.
- 生嶋 竜実, 武田 龍, 合原 一究, 駒谷 和範: "カエルの合唱音声に対する教師ありモノラル音源分離のためのスペクトル構造を用いたデータ拡張", 第36回人工知能学会全国大会, 2022
- 奥野 尚己, 武田 龍, 駒谷 和範: "対話システムにおけるマルチモーダル情報を用いた自己開示の可否判断", 情報処理学会第84回全国大会, Mar. 5, 2022. (学生奨励賞受賞)
- 吉田朋矢,生嶋竜実,武田 龍,駒谷和範:"Vocal Effortの変動に頑健な話者識別のためのフィルタバンク特徴量の設計", 情報処理学会第84回全国大会, Mar. 4, 2022.
- 時末卓幹, 武田龍, 駒谷和範, 翠輝久, 細見直希, 山田健太郎:"不完全な物体検出結果に基づく対話を通じた目的地推定のための質問選択", 情報処理学会第84回全国大会, Mar. 3, 2022.
- 黒田 佑樹, 武田 龍, 駒谷 和範: "システム発話間の整合性を重視した発話選択への深層強化学習の適用", 第93回 言語・音声理解と対話処理研究会, Nov. 29, 2021
- 久保 祐喜, 生嶋 竜実, 二瀬 颯斗, 武田 龍, 駒谷 和範: "ルールと用例を併用してユーザ発話を誘導する対話システムの構築", 第93回 言語・音声理解と対話処理研究会, Nov. 29, 2021 (第4回対話システムライブコンペティション シチュエーショントラック 優秀賞受賞)
- 黒田 佑樹, 武田 龍, 駒谷 和範: "システム発話間の内容的整合性を用いた強化学習に基づく発話選択", 情報処理学会第83回全国大会, Mar. 4, 2021 (学生奨励賞受賞)
- 宗像 北斗, 武田 龍, 駒谷 和範: "モノラル音源分離のための音源間の類似度に基づく学習用混合信号の選択", 情報処理学会第83回全国大会, Mar. 4, 2021
- 生嶋 竜実, 武田 龍, 駒谷 和範: "教師ありモノラル音声分離のための残響音声データ内の単一話者区間を活用した転移学習", 情報処理学会第83回全国大会, Mar. 4, 2021 (学生奨励賞受賞)
- 奥野 尚己, 武田 龍, 駒谷 和範: "対話システムにおける適応的発話選択のためのユーザ状態の設計と推定", 情報処理学会第82回全国大会, Feb. 20, 2020
- Takahiro Ishimaru, Ikkyu Aihara, Ryu Takeda, Tohru Kawabe: "Interaction mechanism of male cicadas (Meimuna opalifera) examined by audio recording and signal processing," The 6th Annual Meeting of the Society for Bioacoustics, 20-22 November 2019.
- 西本 遥人, 武田 龍, 駒谷 和範: "対話コーパスに基づく新たなシステム対話行為の設計の検討", 第10回対話システムシンポジウム, Dec. 3, 2019.
- 赤井 元紀, 武田 龍, 駒谷 和範: "音声対話システムにおける対話の状況を利用した応答タイミング推定", 第32回人工知能学会全国大会, June 6, 2018.
- 大野 航平, 武田 龍, エリック ニコルズ, 中野 幹生, 駒谷 和範: "対話を通じた未知語獲得に向けた暗黙的確認の提案", 第111回音声言語情報処理研究会, Mar. 2016.
- 大野 航平, 武田 龍, エリック ニコルズ, 中野 幹生, 駒谷 和範: "雑談対話における未知語や属性の獲得のための質問生成", 情報処理学会第78回全国大会, Mar. 2016.
- 梶野 尊弘, 武田 龍, 小路 悠介, 駒谷 和範: "マルチモーダル情報からの運転者の内部状態の推定", 情報処理学会第78回全国大会, Mar. 2016.
- 合原 一究, 水本 武志, 武田 龍, 大塚 琢馬, 高橋 徹, 奥乃 博: "アマガエルの多体系発声行動に潜む時空間ダイナミクス", 定量生物学の会・第2回年会, Jan. 2010
- 松山 匡子, 駒谷 和範, 武田 龍, 尾形 哲也, 奥乃 博: "バージイン発話タイミングを導入した指示対象同定", 情報処理学会音声言語研究会, May 2009. (学生奨励賞)
- 合原 一究, 水本 武志, 武田 龍, 大塚 琢馬, 高橋 徹, 奥乃 博, "Time-delayed model on frogs' calling behavior and novel device for localizing calling animals," 第14回聴覚研究フォーラム, Mar. 2009.
- 合原 一究, 武田 龍, 水本 武志, 高橋徹, 合原一幸, 奥乃 博: "ニホンアマガエルの同期した発声行動に関する実験的研究およびその数理モデル解析," ニューロコンピューティング研究会, Mar. 2009.
- 大塚 琢馬, 村田 和真, 武田 龍, 中臺 一博, 高橋 徹, 尾形 哲也, 奥乃 博: "歌唱ロボットのためのビート情報とメロディ・ハーモニー情報の統合による音楽音響信号と楽譜の実時間同期手法の開発", 情報処理学会第71回全国大会, 5R-7, Mar. 2009.
- 松山 匡子, 駒谷 和範, 白松 俊, 武田 龍, 尾形 哲也, 奥乃 博: "実環境音声対話システムにおけるバージイン発話タイミングを活用した指示対象の同定", 情報処理学会第71回全国大会, 4Q-3, Mar. 2009
- 合原 一究, 武田 龍, 水本 武志, 高橋徹, 奥乃 博: "ニホンアマガエル3 匹の同期した発声行動に関する数理的・実験的研究," 第5回「生物数学の理論とその応用」, Jan. 2009.
- 合原 一究, 武田 龍, 水本 武志, 高橋徹, 奥乃 博: "アマガエルの同期した発声行動に関する実験的・数理的研究", (社)音響学会関西支部 第11回若手研究者交流研究発表会, Dec. 2008. (第11回若手研究者交流研究発表会 最優秀賞)
- 村田 和真 中臺 一博, 武田 龍, 奥乃 博, 長谷川 雄二, 辻野 広司: "ビートトラッキングロボットの構築と評価", 第28回 AI チャレンジ研究会, SIG-Challenge-A802-3, pp.13--20, 人工知能学会, Nov. 2008. ((社)人工知能学会 2008年度研究会優秀賞)
- Ikkyu Aihara, Ryu Takeda, Toru Takahashi, Takeshi Mizumoto, Hiroshi G.Okuno: "Experimental and Theoretical Studies on Synchronized Calling Behavior of Three Japanese Tree Frogs", Japan-Slovenia Seminar on Nonlinear Science, Nov. 2008.
- 水本 武志, 武田 龍, 吉井 和佳, 高橋徹, 駒谷 和範, 尾形 哲也, 奥乃 博: "聴覚機能を持つ音楽ロボットのためのアーキテクチャの設計とビートカウントロボットへの適用", 26回ロボット学会学術講演会, 1A1-02, Sep. 2008.
- 水本 武志, 武田 龍, 吉井 和佳, 駒谷 和範, 尾形 哲也,奥乃 博: "音楽と自分の声を聞き分けながらビートに合わせて発声するロボットの開発", 情報処理学会第70回全国大会, 2X-8, Mar. 2008.
Patents
- 特願2021-35253(P2021-35253) 特許第7577276号(P7577276)・中臺 一博, 武田 龍・音響処理装置、音響処理方法およびプログラム・本田技研工業株式会社, 国立大学法人大阪大学・2021年03月05日.
- 特願2020-183848(P2020-183848) 特許第7427200号(P7427200)・中臺 一博, 福本 陽典, 武田 龍・ノード枝刈り装置、ノード枝刈り方法、およびプログラム・本田技研工業株式会社, 国立大学法人大阪大学・2020年11月02日.
- 特願2014-204406(P2014-204406) 特許第6427377号(P6427377)・武本 剛, 本間 健, 武田 龍, 齋藤 仁, 畑山 正美, 三浦 春好, 天野 亘・設備点検支援装置・株式会社日立製作所, 東京都下水道サービス株式会社・2014年10月03日.
- 特願2014-192548(P2014-192548) 特許第6284462号(P6284462)・武田 龍, 本間 健, 武本 剛・音声認識方法、及び音声認識装置・株式会社日立製作所・2014年09月22日.
- 特願2014-190183(P2014-190183) 特許第6254504号(P6254504)・藤田 雄介, 武田 龍・検索サーバ、及び検索方法・株式会社日立製作所・2014年09月18日.
- 特願2015-536346(P2015-536346) 特許第6074050号(P6074050)・藤田 雄介, 武田 龍, 神田 直之・検索サーバ、及び検索方法・株式会社日立製作所・2013年09月11日.
- 特願2013-178542(P2013-178542)・武田 龍・音声データ認識システム及び音声データ認識方法・株式会社日立製作所・2013年08月29日.
- 特願2015-511040(P2015-511040) 特許第6157598号(P6157598)・住吉 隆志, 大淵 康成, 神田 直之, 武田 龍・移動ロボット、及び、音源位置推定システム・株式会社日立製作所・2013年04月12日.
- 特願2014-532631(P2014-532631) 特許第5897718号(P5897718)・武田 龍, 神田 直之, 大淵 康成, 住吉 貴志・検索サーバ、及び検索方法・株式会社日立製作所・2012年08月29日.
- 特願2010-124873(P2010-124873) 特許第5550456号(P5550456)・中臺 一博, 中島 弘史, 奥乃 博, 武田 龍・残響抑圧装置、及び残響抑圧方法・本田技研工業株式会社・2010年05月31日.
- 特願2010-105369(P2010-105369) 特許第5572445号(P5572445)・中臺 一博, 武田 龍, 奥乃 博・残響抑圧装置、及び残響抑圧方法・本田技研工業株式会社・2010年04月30日.
- 特願2009-166048(P2009-166048) 特許第5337608号(P5337608)・中臺 一博, 長谷川 雄二, 辻野 広司, 村田 和真, 武田 龍, 奥乃 博・ビートトラッキング装置、ビートトラッキング方法、記録媒体、ビートトラッキング用プログラム、及びロボット・本田技研工業株式会社・2009年07月14日.
- 特願2009-166049(P2009-166049) 特許第5150573号(P5150573)・中臺 一博, 長谷川 雄二, 辻野 広司, 村田 和真, 武田 龍, 奥乃 博・ロボット・本田技研工業株式会社・2009年07月14日.
- 特願2008-191382(P2008-191382) 特許第5178370号・武田 龍, 中臺 一博, 辻野 広司, 奥乃 博・音源分離システム・本田技研工業株式会社・2008年07月24日.
© 2016 Ryu Takeda
Toolkit
pyadintool
- A pre-processing toolkit covering voice activity detection, recording, splitting and sending of audio stream.
- ASR examples using ESPnet, etc... are also included.
ESPnet ASR extrakit
- Simple examples for model training and evalution.
- Patch files for character-level probability, WFST LM, and MD-ASR.
ASR-ja Evaluation Kit
- A sample toolkit considering orthographic variants (表記ゆれ) for evaluation of Japanese automatic speech recognition (ASR).
- Sample evaluation scripts for open corpora
Model
ESPnet ASR models (for Japanese)
- Robust pretrained models for a noisy and reverberant input
- "Katakana" models for phoneme/syllable-like recognition
- Model parameters for streaming ASR (contextual block transformer) are also provided. See ASR examples in pyadintool.
© 2016 Ryu Takeda